Hadoop Application Architecture Examples
There are several posts, blogs, and white papers on Hadoop Application Architectures. Patterns have been named: lambda, kappa etc. Jargons has developed, most notable is 'Data Lake'. Regardless of what a system is called, Hadoop and its ecosystem components are used in predictable ways. For example,
- HDFS is the de facto standard for long term storage
- Stream processing would involve kafka and spark or storm
- HBase would come into play for unstructured data with real-time or near real time application needs
- Search/Indexing would use either Solr or ElasticSearch
We kind of know the basic building blocks. We know underlying technologies. Which building blocks to choose depends on what and how much data we have, with some understanding of an end goal with it. That end goal may be long term storage, real time processing and/or access, batch processing or reduced latency among legacy components of a system. Implementations differ in the choice of language and tool set. One project may use python, another java and some other scala. Tech selection is not the biggest of the problems, what to do with the data is! Most of the time all these new tools/frameworks work with all other usual legacy components; Like reading/writing data from/to a database, using application caches, using messaging queues etc.
In this post, I will try and present my thoughts on arranging Hadoop ecosystem components with possible end goals in mind. Even when one does not know lambda/kappa or any other fancy architecture pattern name, it is easy to see how and why certain components fit together and how they enable different kinds of processing out of the box. Use hdfs to store streaming data and batch is enabled automatically. Now, if one writes few hive queries or map reduce jobs on top of this stored data, you can see how you have just implemented 'lamba' architecture! Of course, this is a very naive example but bring a more systematic approach to it and things become very interesting and you would want to name your setup as a new architecture pattern.
Use case
Let’s say we have a stream of events that we need to process. These events can be banking transaction, gaming events or commands fired against a service. In such cases the order of transactions are important. We want to preserve that order and process events/data in that order only. This calls for non-duplicated, once only delivery of events.
We want an ability to
- quickly display some or all events on a dashboard
- reply those transitions at a later stage to test or to investigate, which means we need to store them in order as well.
- derive new forms of data from this base data set by performing transformations which may include enriching it with data from other sources.
The above are our end goals. Based on that let's derive a few other requirements/end goals:
\ta. A part of the system with latency requirement of <50-100 ms
\tb. Another part with latency requirement of >100 ms but < 1-5 secs
\tc. Batch processing
Examples
a. Latency < 50-100 ms
For these applications, there is little scope for event alterations. Events need to be delivered as and when they come. The tools we use need to support that.
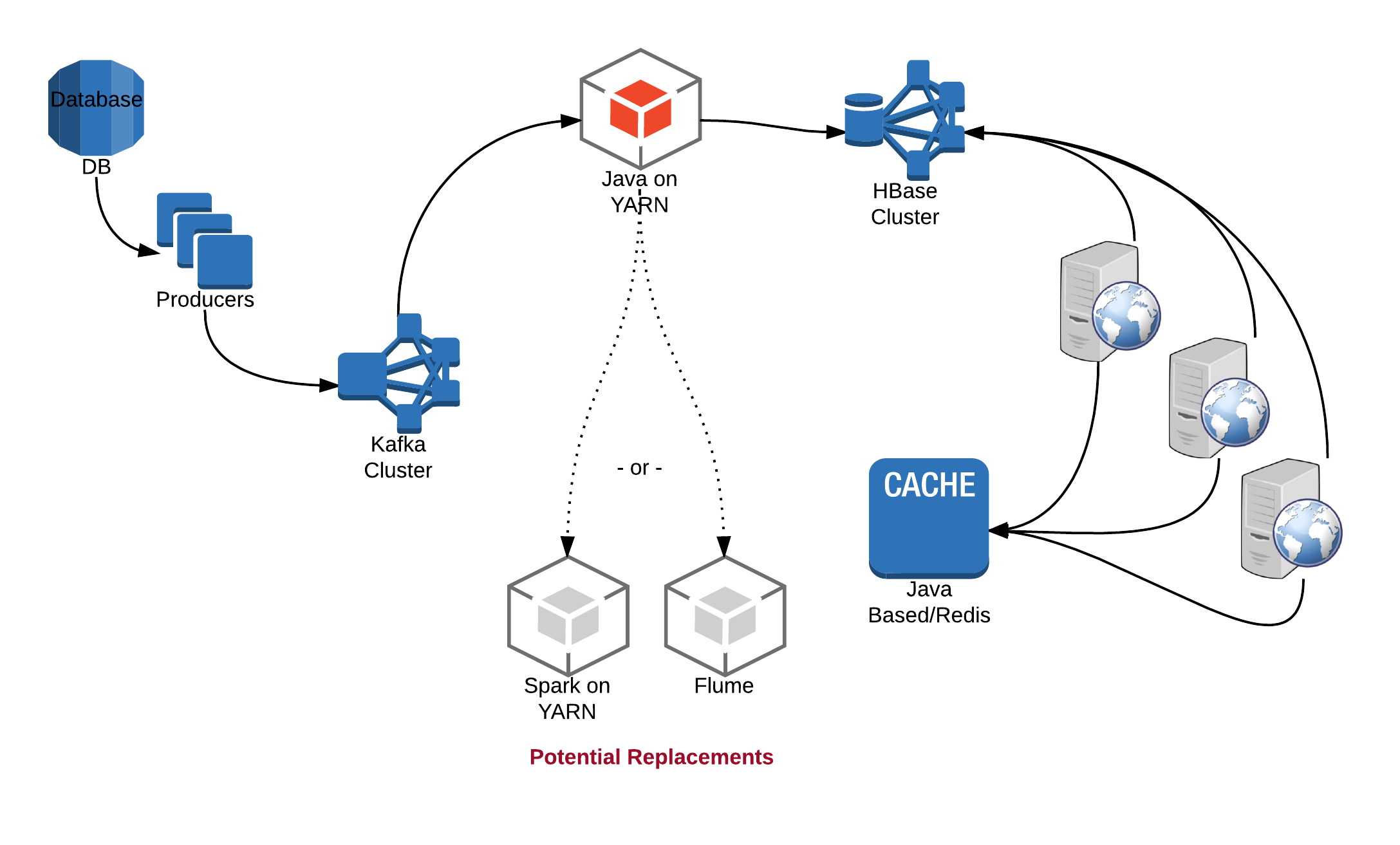
With the above setup, we can achieve milliseconds end to end latency. In most case data comes from a database or is user generated. That data can be safely stored in a Kafka cluster with appropriate delivery semantics. Once data lands in Kafka, we can configure it to persist for a time period of our liking.
We can consume this data off Kafka from:
- a Java application running on YARN or
- a Spark application running on YARN or
- we can use Flume
Or we can use plain old map reduce jobs with something like Linkedin camus or now gobblin.
We can do whatever small amount of processing we need to do on this data like de-serialisation or unzipping etc. We can then store this into an HBase cluster. Hbase is optimised for heavy reads and can handle several thousand writes easily. Coming up with a right, working schema may be a challenge but it is doable with some experience. Obviously, there would be some amount of tuning/tweaking to get Kafka and Hbase cluster sizes right.
From Hbase, web servers or application servers can read data, may store it in some form of cache and deliver it to end clients.
One can ask about how to choose between Java, Spark and Flume. It depends on overall team skills, future plans, ease of use and several other criteria. An argument in favour of Spark would be ease of development and consistent APIs for batch and streaming applications.
This setup allows us to handle incoming stream of data and delivery it in real time, it also stores this data in Hbase/HDFS for us. That enables further near real time and batch processing.
b. Latency >100 ms but < 1-5 secs
Now, armed with this knowledge that we have this data stored in HBase, let’s say we need a CSV file at the end of the day (for all transactions in a bank or all events in a game play). We can build upon what we have.
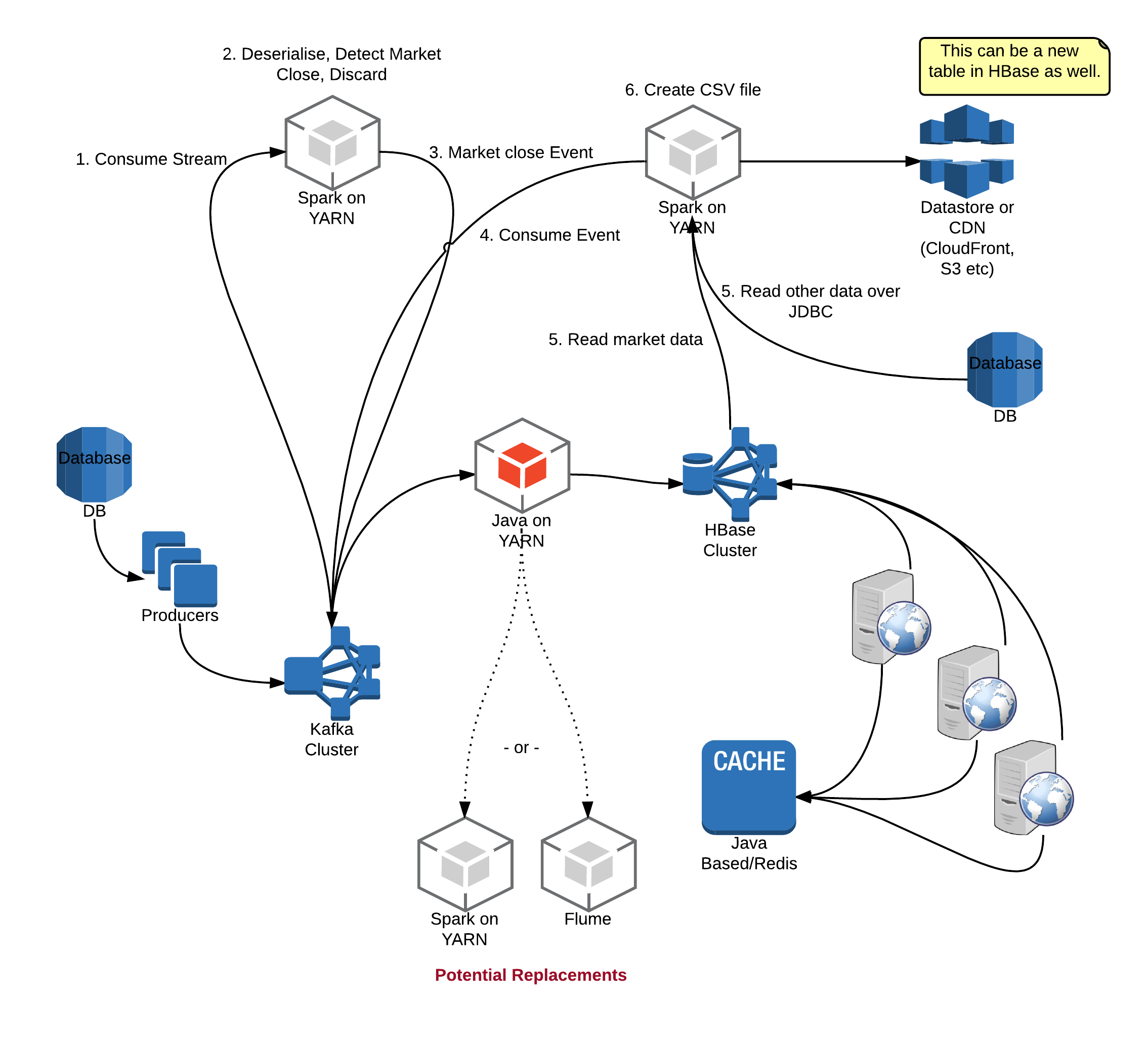
We can consume a Kafka topic to detect event close or day end. And then chain Spark or Java applications to create a CSV file. As we can see, it builds on top of our streaming application. We can add more sophisticated applications or services on this base layer.
c. Batch
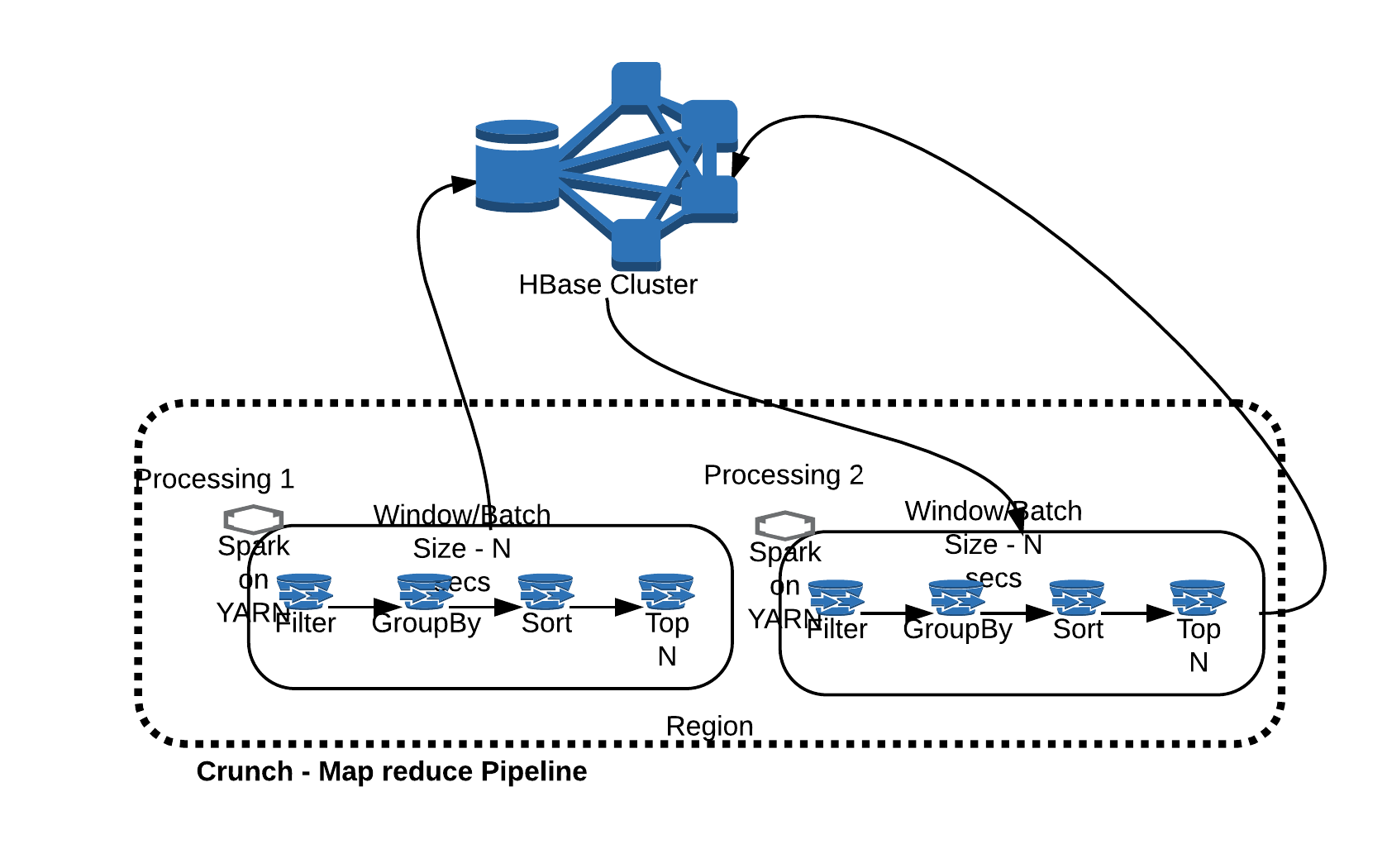
Batch processing can happen on the same infrastructure with similar technologies. We can go for map reduce based data pipelines or spark based pipelines. Both ways we can utilise what we already have. Apache Crunch is a framework that allows us to create and manage data pipelines. Again, tools choice can differ, we still utilise the same Hadoop/HBase infrastructure.
Naming these patterns?
Who cares? As long as it works! We need to understand how to stitch together all the different Hadoop ecosystem components; a system would come up to serve a specific purpose. By design these components allow interoperability. It is crucial to understand the end goals, understand what is needed to be done with the data; tech and tools would fall in place with clear understanding of each technology's strengths and weaknesses.