Hadoop Tutorial for Beginners
Can you give me a quick Hadoop 101? or Can you give the team a tutorial on What is Hadoop? are some of the questions I get in almost all my engagements. These are the questions I get asked from friends, colleagues and everyone else who want to learn Hadoop. A quick googling results in lots and lots of good links but somehow those links are failing to enlighten potential Hadoopers to understand what it is? If those links worked, I guess, I should not be getting such questions. I personally find several of those links to be quite good but they do not work apparently.
I, therefore, would try and write a basic but slightly detailed post that would help beginners understand Hadoop concepts. I would not go into details as how Hadoop started or why Doug Cutting named it Hadoop. Those are well known Hadoop folklore.
An interesting point to note though is that Hadoop was initially part of Apache Nutch project. It grew out of nutch to become one of the most successful open source projects, which created an entire industry!
Because of the success of Hadoop, there has been an explosion of tools/technologies/frameworks that work with Hadoop or work on top of Hadoop. Such rapid expansion of tech stack has led to a lot of confusion to beginners as to what Hadoop Stands for?
Hadoop, Hadoop framework and Hadoop eco-system are all used interchangeably. Personally, i would use Hadoop and Hadoop framework to mean the same thing (explained below) and use Hadoop eco-system to refer to all abstractions on top of Hadoop and all things that work with Hadoop.
Level 0
Before we get into details of what is Hadoop and how it works etc., we need to get a clear understanding on few things.
Common Terminology
Here is list of common terms encountered as soon as one starts learning Hadoop.
- Cluster
- A cluster is a group of machines/servers that work in tandem to solve a problem.
- Nodes
- A single machine/server in a cluster is called a Node.
- Scale Horizontally
- is a property of a distributed system that allows us to add more servers under increased load. Instead of adding more RAM or CPU on a single instance, we add a new machine in a cluster.
- File System
- In operating system parlance, a file system keeps track of files on a disk(s) and governs the way files are organised and accessed.
What Hadoop is not?
Hadoop is not a database and it is not intended to replace all of your relational and BI databases in an enterprise. It is not NoSQL and it is not MPP.
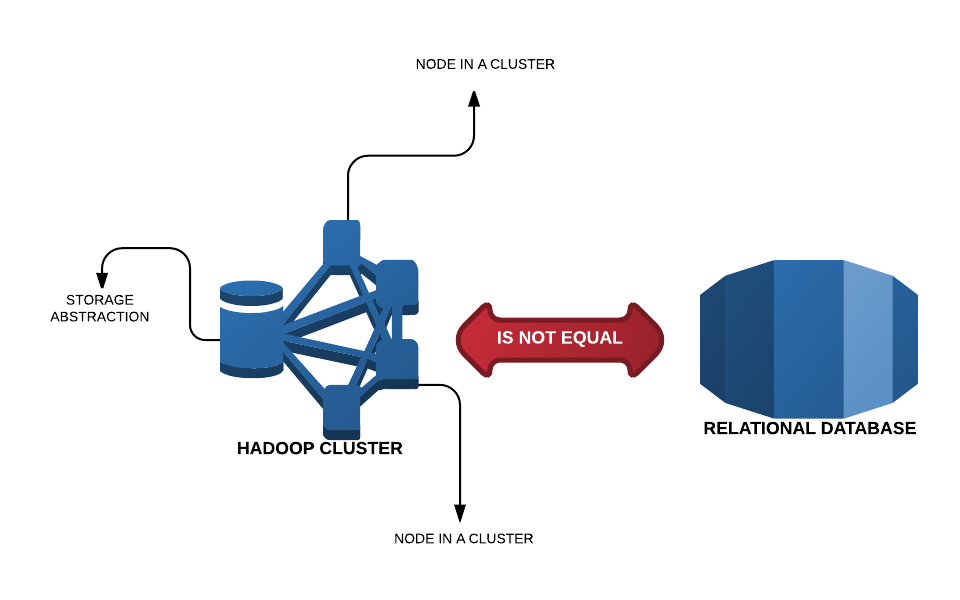
You do not get tables out of the box and you do not run queries after installing Hadoop. To get all these, you would need to work with higher level abstraction built on top of Hadoop such as Hive, Pig, Impala, Drill etc.
What is Hadoop?
"Hadoop is Unix of data processing" is how I would describe hadoop in one sentence. Although this was not true when hadoop initially started and it was not a goal. It happened in quick time.
Hadoop is a framework to build large-scale, shared storage and computing infrastructure to solve embarrassingly parallel problems.
Hadoop is data storage and processing system designed such that, it:
- runs on commodity hardware
- handles petabytes and zetabytes of data
- runs on multiple machines
- scales horizontally
- provides an easy abstraction for data storage and processing
- handles failure
- provides replication out of the box
Each of the bullets above translates into complex code that went into creation of Hadoop. All above are covered by two basic building blocks in Hadoop/Hadoop framework:
- HDFS (Hadoop Distributed File System): Storage
- Map Reduce: Processing
As I have said before, hadoop is not a database. It provides a storage layer, that deals with files. There is no DBMS out of the box.
Hadoop has a master/slave architecture. So both the above components have one master process and several slave processes. Master and slave processes may reside on the same box but are usually run on different machines.
HDFS has a master process called Name Node and several slave processes called Data Node. Similarly, Processing unit has a master process called Job Tracker and several slaves called Task Trackers.
HDFS
Why does Hadoop need a new File System? All the machines on which Hadoop gets installed already has a native File System, e.g. Linux would have ext3, windows would have NTFS.
Hadoop needs its own File System because of amount of data it handles and the way it needs to store and process data. Lets first try and understand what happens when we store a file on a day-to-day basis on our laptops, servers.
File Storage
When one stores a file on disk, it is stored in chunks on disk, like below:
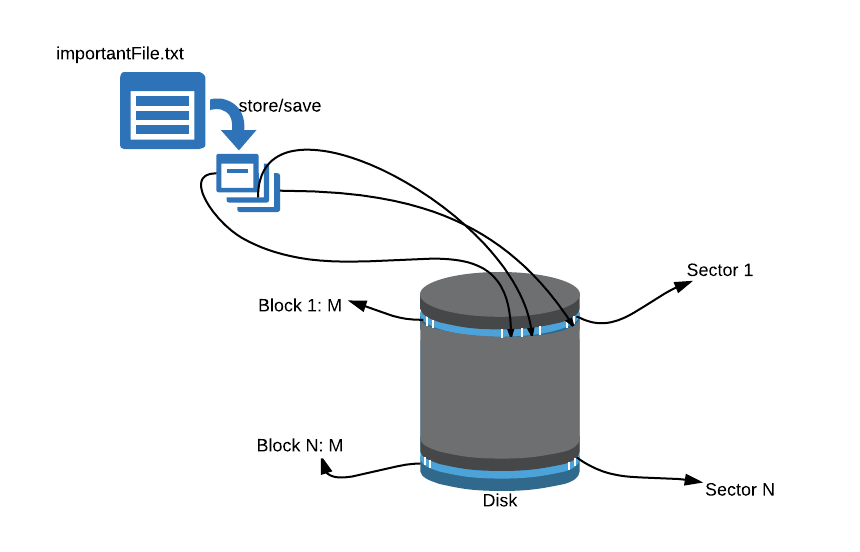
Each disk is divided into sectors and each sector has several blocks. One block is generally 4K bytes. For example, when one stores a file of 12KB in size, it would take up 3 blocks on disk. The operating system would keep a track of physical disk locations (inside what is called File Allocation Table) belonging to all files in the system. While reading this file, the disk would have to make 3 seeks.
Imagine storing a 1GB file in this way,
block size = 4K
file size = 1GB
No of blocks written = 1GB/4K = 250KNow imagine writing TBs of data/files like this. You get the point, we end up doing lots and lots of disk read writes. Also, what do you do if you wanted to read faster?
Since one of the goals of hadoop is to enable handling of huge amounts of data, it needed a way to store huge amounts of data efficiently. Obviously, it cannot rely on the underlying OS's file management capabilities, as those would prove to be slow in terms of storage and retrieval. A single machine can only store a finite amount of data on its disk, but hadoop wanted to store petabytes of data across an array of commodity machines.
And that is precisely why hadoop needed its own file system, HDFS or Hadoop Distributed File System. HDFS is a file system with a default block size of 64MB (it is 128MB on Cloudera distribution). So storing a 1 GB file on HDFS would mean:
block size = 64MB
file size = 1GB
No of blocks written = 1GB/64MB = 16A 1 GB file can now be read in only 16 disk seeks at worst, than 250K disk seeks at worst case on a normal OS file system. It is important to note here that because the default block size is 64MB hdfs is not well suited for small size files. Storing a 10KB file would end up taking 64MB in hdfs.
HDFS provides abstraction for (in very general terms and at the most basic level):
- Storing huge files over several machines while hiding details of how and where it is stored.
- Reading a huge file while managing and reading several of its blocks from several machines on network.
- File operations like create, delete, move
The way a OS's file system has a File Allocation Table, HDFS also needs to maintain a registry of which files are stored where. That registry is called Name Node. Name Node stores metadata about all the files in the system. Actual data is stored and managed by another entity called Data Node. Both Name node and Data node are nothing but Java processes running on nodes in a hadoop cluster.
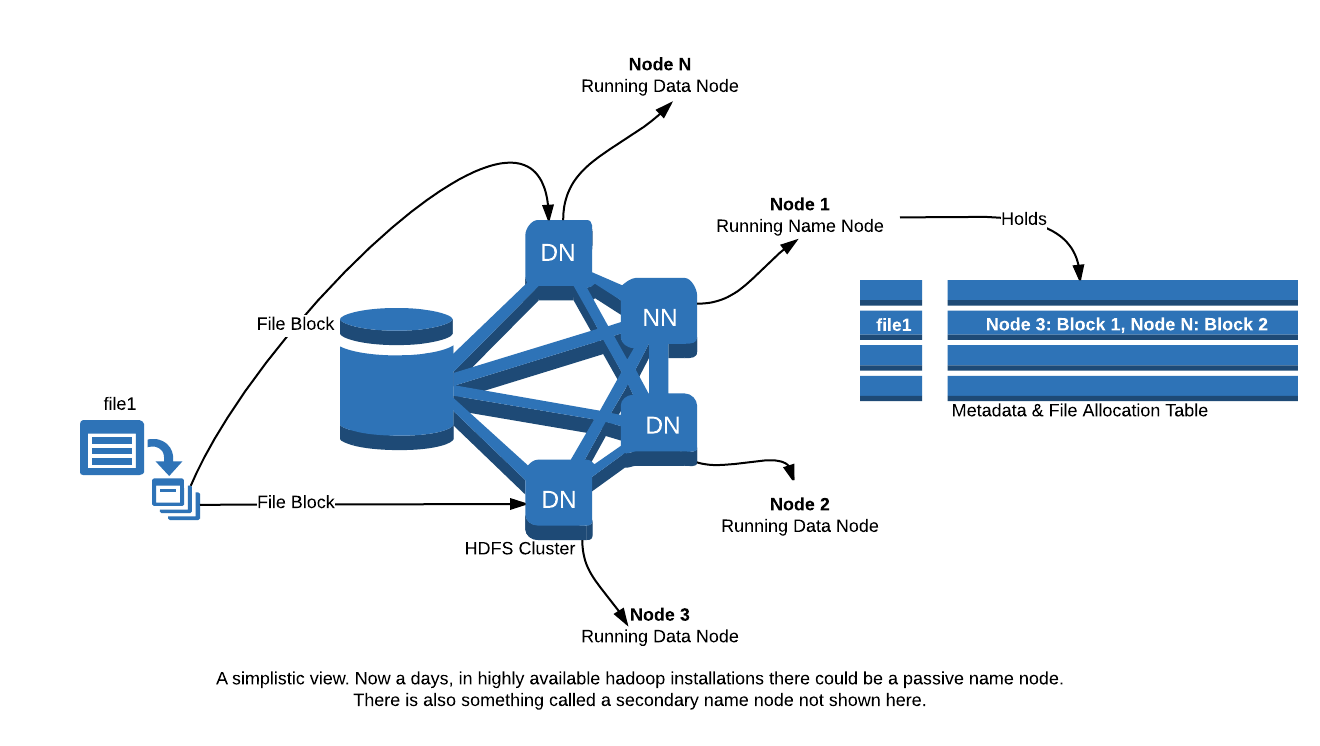
Above is a very simplistic view of HDFS. Obviously there are complexities involved not suited for this post. I have also omitted:
- Secondary Name Node: it is again a java process that helps the name node in keeping file system logs. (Again, in very simple terms. A system wide image or snapshot is kept, called fsimage, and that is kept updated from time to time with latest changes from edit logs.)
- StandBy Name Node: this is a hot standby name node used for quick failover in a Highly Available cluster.
We can safely defer more details on these two until we gain enough understanding about overall hadoop infrastructure.
How does it all work?
Name node and Data node is all fine, you say, how does it all work? How do the nodes know that others exist in the cluster and how is the cluster formed? All this is done in Hadoop with some very smart concepts:
- All data nodes need to know their name node's address. All these nodes then send their details to Name node and Name node then forms a cluster of nodes.
- All the data nodes send a periodic 'heartbeat' to the name node. This is a signal that says 'i am alive'. In absence of a 'heartbeat' for a certain amount of time (configurable), name node would mark that particular data node as dead and stop assigning any work to it, like giving data for storage or sending a request for retrieval.
- Data is replicated by default 3 times. In case of a node failure, we always have a copy of the data on some other node in the cluster. For those who instantly came up with "what happens if a full rack of nodes in a data center fails?” well, hadoop provides a setting for being 'rack aware'. When specified, replica copies would be stored on a different rack.
- All external processes that wish to read and/or write data from/into HDFS contact Name Node first to get file metadata.
And there are many more, i think the above are one of the most important ones.
Map Reduce
All good with data storage. How do we run anything on this data? How do we utilise terabytes and petabytes of data we have stored into HDFS? How is hadoop faster when compared to other solutions?
Solutions prior to hadoop worked on the premise that data could be stored across a network of nodes/machines and to process this data a system must move this data to a powerful processing unit. Such solutions defeated themselves the moment they decided to move huge amounts of data across network. Hadoop inverts this understanding and works by moving the processing to data. How?
When processing is required on a file, processes are scheduled on the nodes with a local copy of the data. Important to note here is the fact that a file has many blocks and these blocks are stored on different nodes and their replicas are stored on other nodes. When a file is needed for processing, a process called the Job Tracker, contacts the Name node for file metadata and asks Task Trackers running on different nodes to launch Tasks. The job tracker is smart in deciding which task trackers to call for launching tasks; this is based on the info about where file blocks are located.
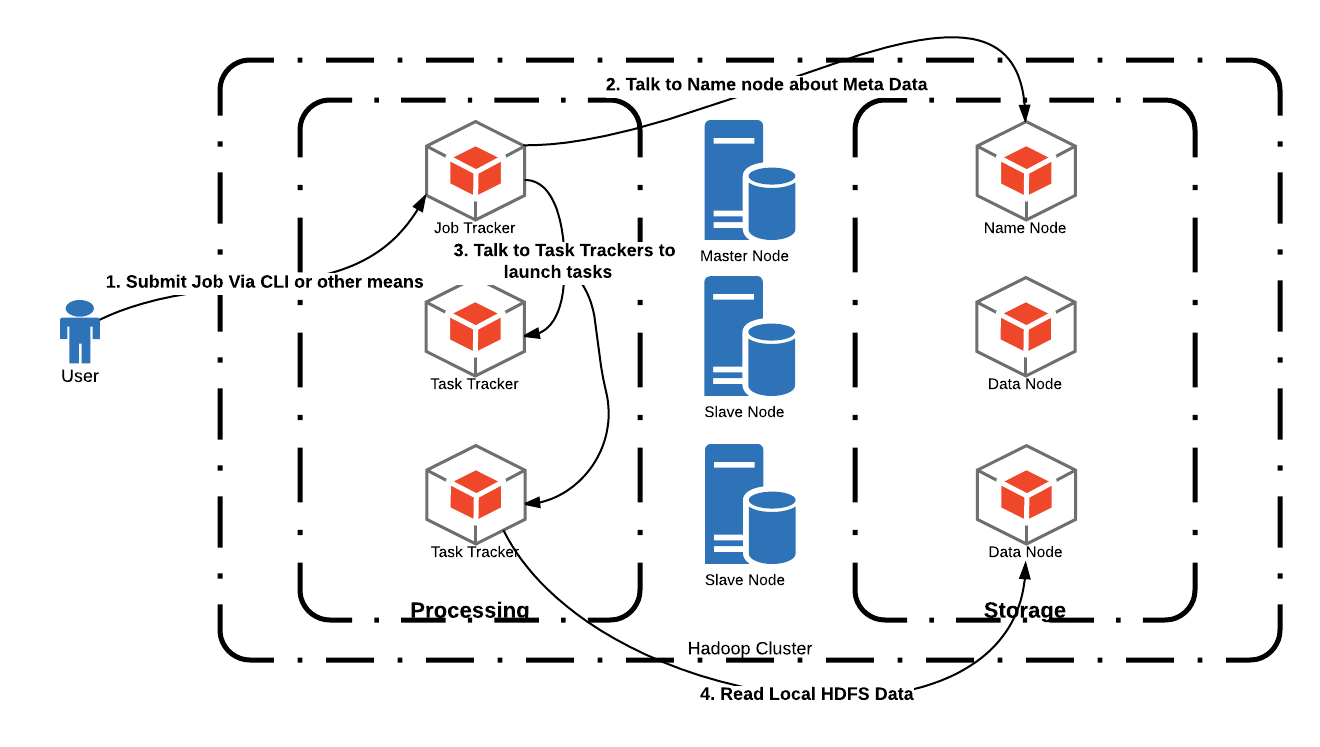
And by not moving huge amounts of data across network and by working on chunks of file in parallel, hadoop manages to achieve faster processing times on massive amounts of data. The speed at which data can be processed now becomes a function of how many large blocks a file can be divided into and how many tasks one can run in parallel. One can add more nodes in the cluster to speed up processing, and this is called Horizontal Scaling. This is in contrast to Vertical Scaling where more CPU and/or RAM is added to a single machine.
But where is map/reduce master? asks the grasshopper.
One of the early and only mechanisms to process data stored in HDFS was a programming paradigm map/reduce. In this way of problem solving, we always work on key, value pairs. Both the key and value can be anything. It can be String keys and String values or Byte keys and Integer Values or anything else. Also, in this paradigm data is not shared among the running maps or reduces. This non-data-sharing also speeds up processing. (For readers interested in more details, please follow the yahoo link below. There is a shuffle phase where data gets copied across machines but that is the only time when individual nodes talk to each other. For most part of the processing, individual nodes work in isolation.)
All processes (or map/reduce jobs) have two broad steps: a map phase and a reduce phase. I say broad, as there is several sub steps involved. A very good explanation is in the original hadoop tutorial on yahoo.
Map: is a function that applies some business logic on incoming data to transform it into an output data point. Final output is grouped on a key.
Reduce: is a function of aggregating or condensing values for a given key.
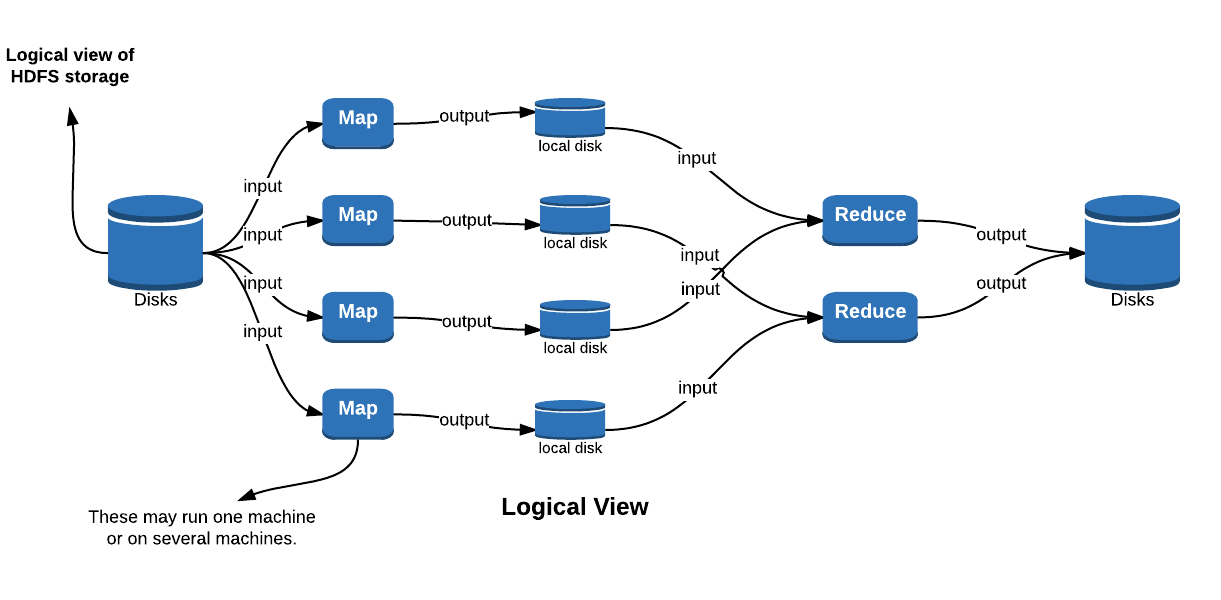
Both map and reduces phases are executed by the Task Trackers in Hadoop. A job is first submitted to the Job Tracker which asks certain Task Trackers to run Tasks. These tasks are map phases to begin with and once maps are done, new reduce tasks are created. The framework makes sure that map tasks get a chunk of data and reduce tasks get the output of map tasks.
How does it work, again? Without sql?
With no database and system dealing with files only, it is natural to ask as to why would it ever work? Or how does this work on files?
Hadoop works with files. The storage unit is a file and not a record. To work with pure map reduce (i say pure map reduce as there are now many more powerful abstraction available on top of hadoop like sql, streaming, columnar storage to name a few) one would need to rethink data models and data storage in a peculiar way. For example, working with server logs. These can be read as files and each mapper would emit a server ip address as key and error message as value. A reducer would then get all error messages belonging to a server IP address and it can then group them by their type.
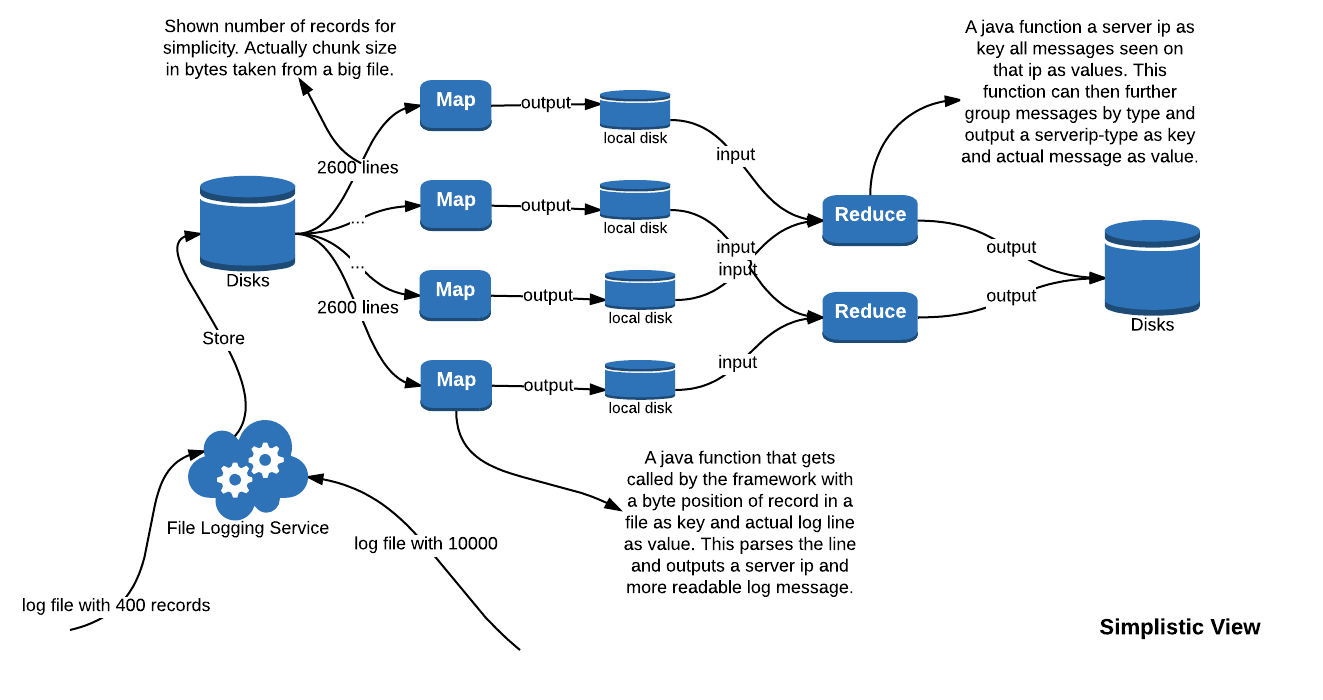
The framework provides all plumbing, users are only required to provide two functions in terms of java code: a map function and a reduce function. Everything else is taken care of.
We are Hadoopy!
It is clear that Hadoop is complex software and there are many moving parts. It is this complexity that creates difficulties for someone new.
I guess this much is more than enough information to grasp hadoop basics and become hadoopy! I may have missed some of the details, would love to receive feedback around that. I will write a post about getting started technically later.
I hope that this conceptual post makes sense and benefits a beginner. Questions, comments, suggestions and criticism are all welcome either in comments section below or over twitter or email